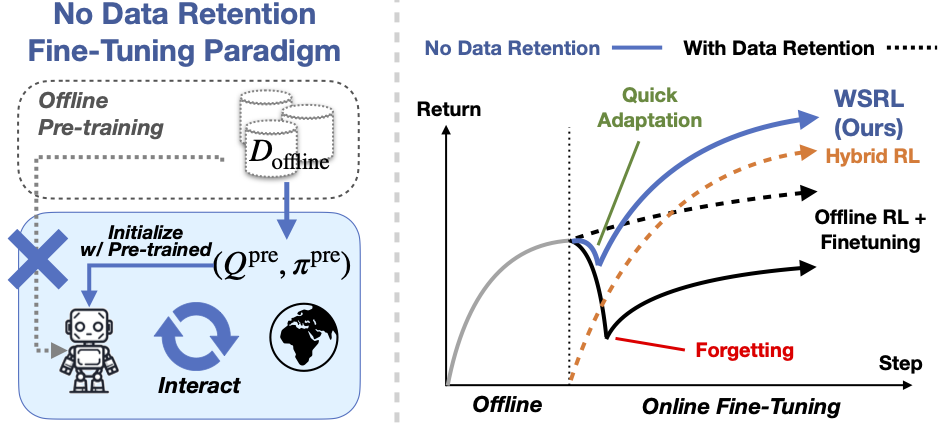
We introduce Warm-start RL (WSRL), a recipe to efficiently finetune RL agents online without retaining and co-training on any offline datasets. The no-data-retention setting is important for truly scalable RL, where continued training on the big pre-training datasets is expensive. However, current methods fail catastrophically in the no retention setting. We show that this is because the sudden distribution shift causes Q-values to diverge on a downward spiral during the re-calibration phase at the start of fine-tuning. WSRL uses a simple idea: pre-train with offline RL, then use a warmup phase to seed the online RL run with a very small number of rollouts from the pre-trained policy to do fast online RL. We find that WSRL significantly outperforms baselines in the no-retention setting, and is also able to outperform methods that retain offline data.
WSRL enables highly efficient RL fine-tuning on real robots! We compare WSRL against SERL on franka peg insertion. Initialized from an offline CalQL checkpoint, WSRL finetunes to a perfect 20/20 success rate in just 18 minutes (roughly 5k warmup + 3k actor steps, 7 minutes without including warmup), whereas SERL fails (0/20) even with 50 minutes.
The modern paradigm in machine learning involves pre-training on diverse data, followed by task-specific fine-tuning. In RL, this translates to learning via offline RL on a diverse historical dataset, followed by rapid online RL fine-tuning using interaction data. Such a setting is important for truly scalable RL, where the offline dataset is big such that its continued training online is expensive; furthermore, if pre-training is effective and fine-tuning done right, the pre-training should already capture the knowledge of the offline dataset, removing the need for co-training (such as current practices in LLMs). However, we find that without retaining offline data, current RL algorithms (e.g IQL, CQL, CalQL) fail catastrophically.
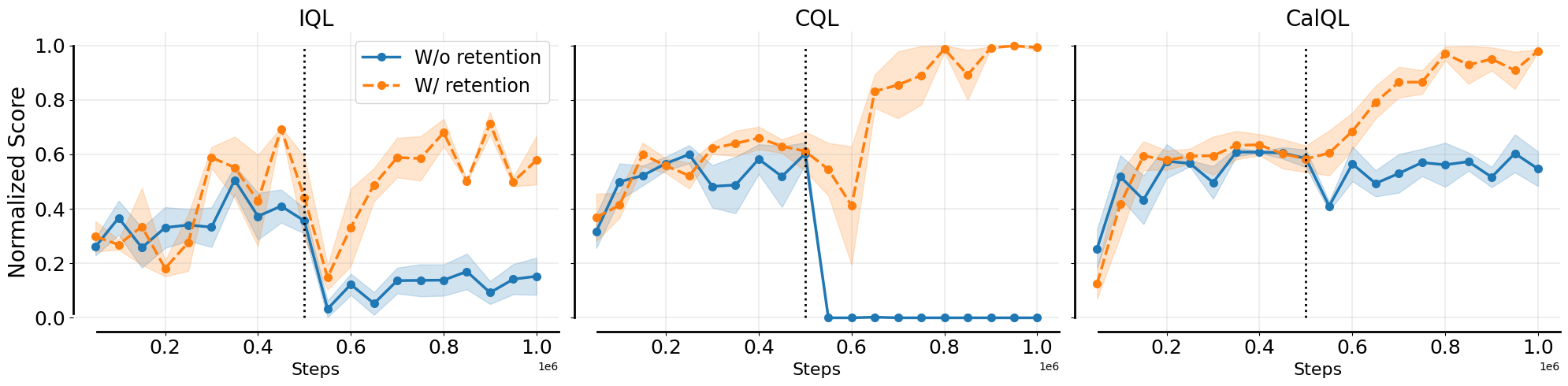
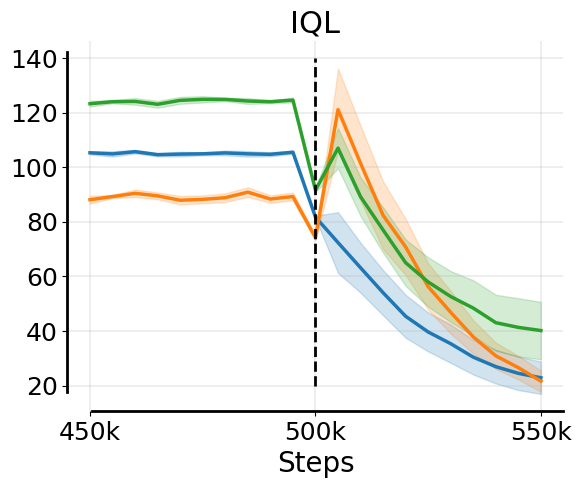
Training only on online experience during fine-tuning without offline data retention can destroy how well the model fits offline data due to the distribution shift between offline dataset and online rollout data: while TD-errors on the online data are comparable regardless of whether offline data is retained, TD-errors under the offline distribution increase noticeably when offline data is not retained.
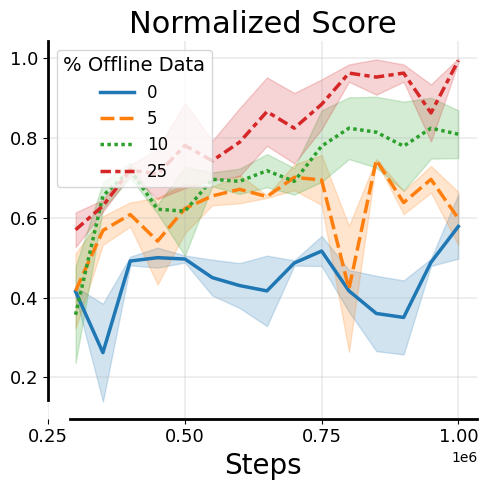
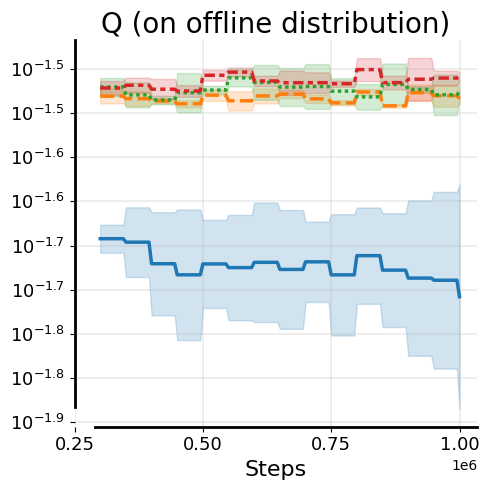
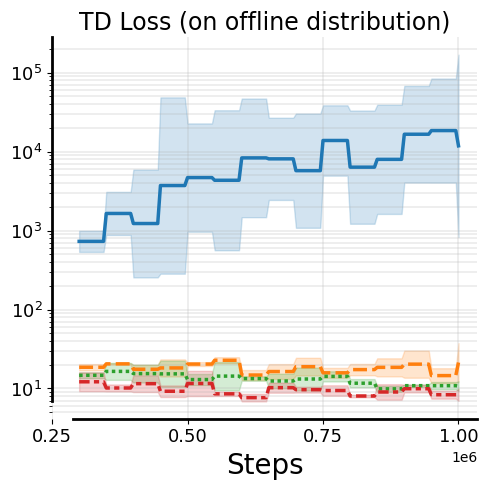
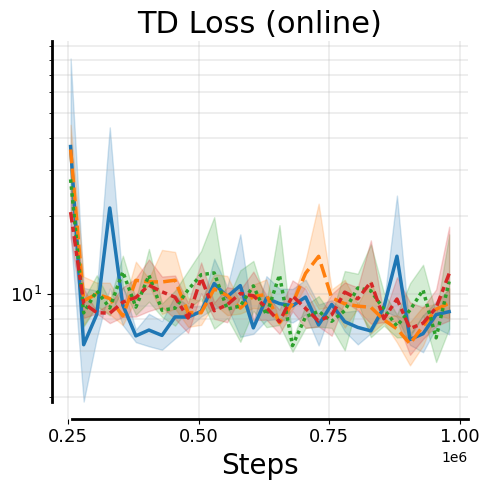
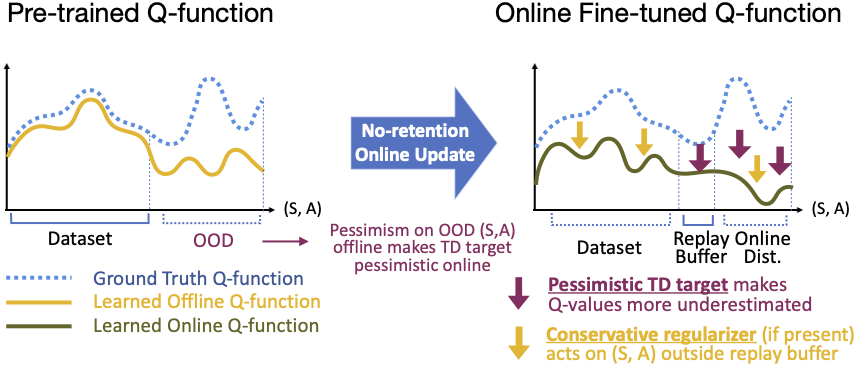
We observe that not only do Q-values diverge on the offline distribution, Q-values on the online distribution also go through underestimation at the onset of no-retention fine-tuning. We find that this excessive underestimation is because of backups with over-pessimistic TD-targets during Q-value recalibration. See evidence and a mechanistic understanding of this downward spiral below.
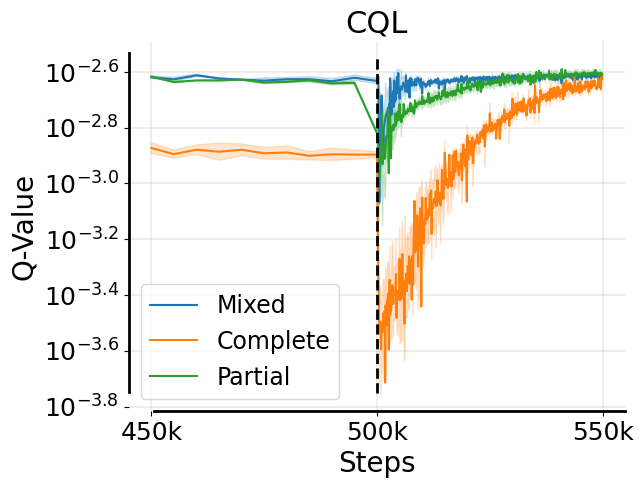
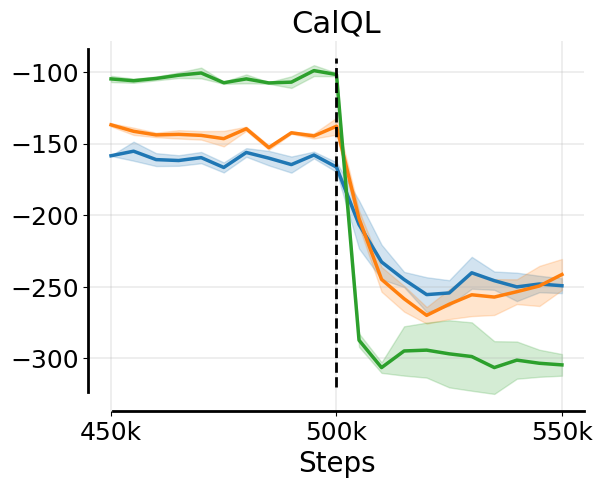
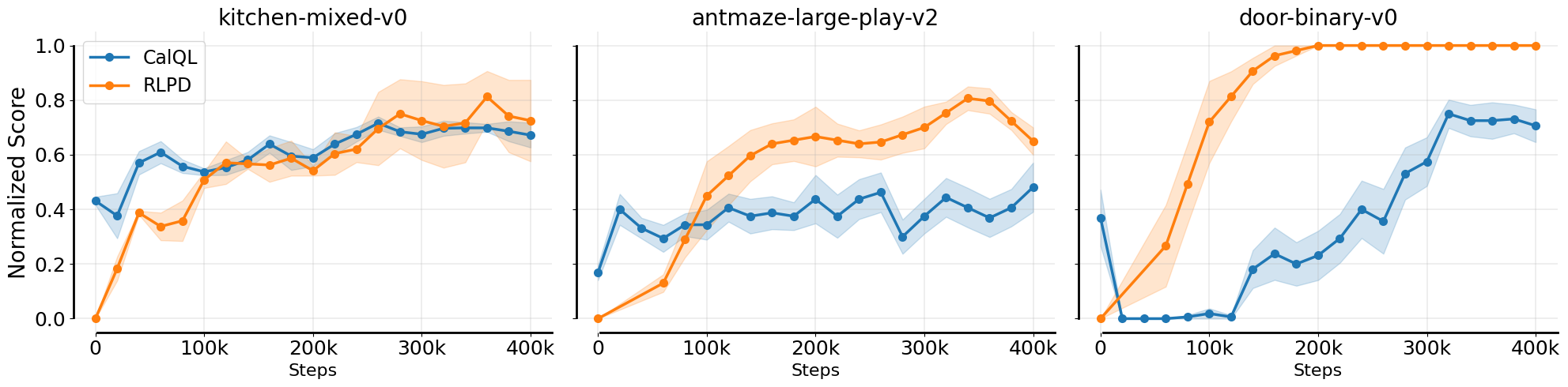
While retaining offline data appears to be crucial for stability at the beginning of fine-tuning for current fine-tuning methods, continuing to make updates on this offline data with an (pessimistic) offline RL algorithm hurts asymptotic performance and efficiency. Specifically, we find that offline RL fine-tuning that co-trains on offline data (e.g. CalQL) is substantially slower than online RL algorithms from scratch (e.g. RLPD).
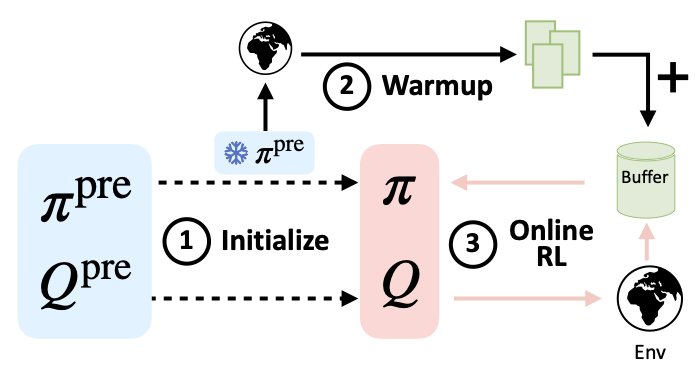
Warm-start RL (WSRL) is a simple and practical recipe that obtains strong fine-tuning results and quickly adapts online without using the offline dataset during online updates. It is composed of three phases:
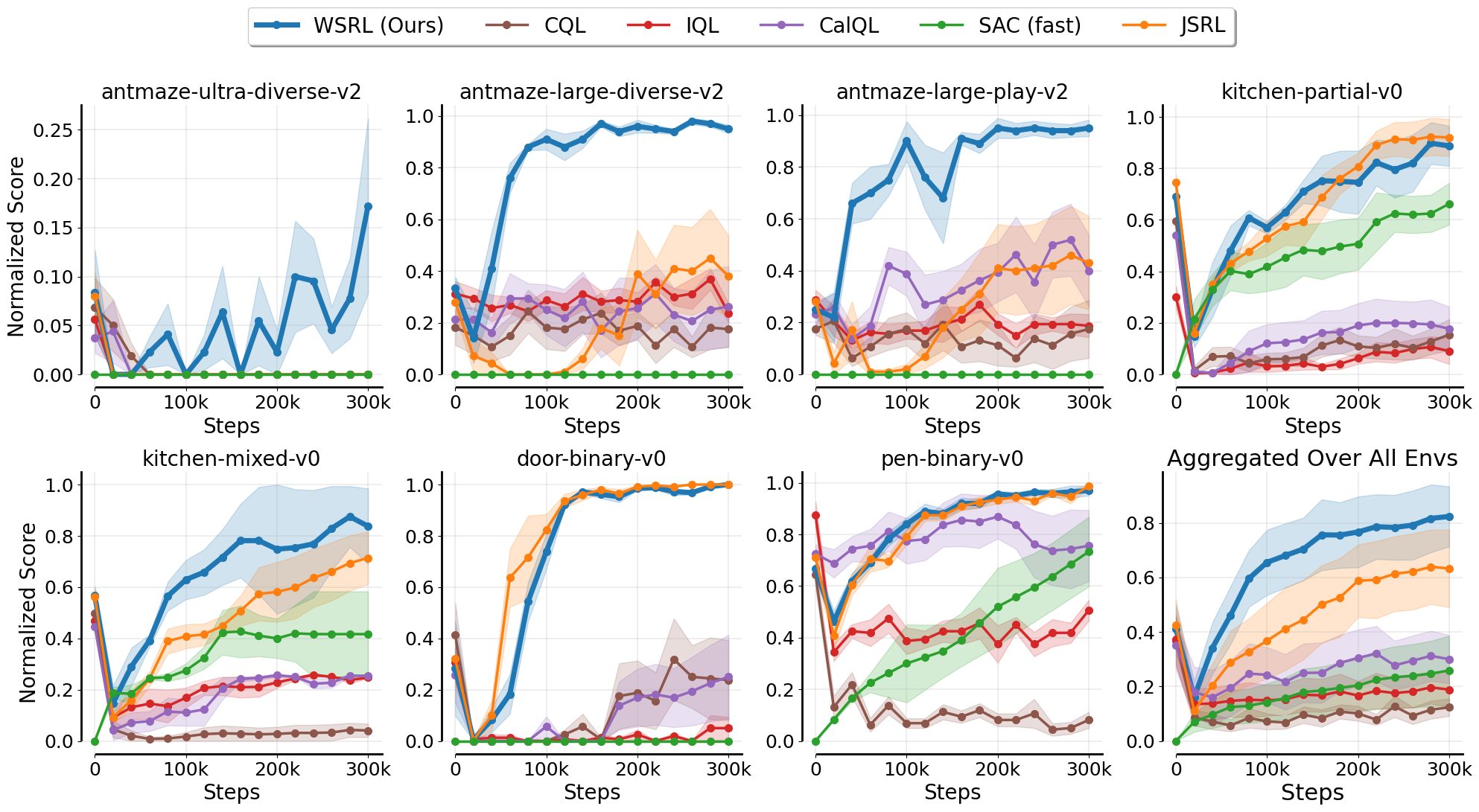
In no-retention fine-tuning, WSRL fine-tunes efficiently and greatly outperforms all previous algorithms, which often fail to recover from an initial dip in performance. JSRL, the closest baseline, uses a data-collection technique similar to warmup. Please refer to the paper for ablation experiments showing the importance of (1) warmup, (2) using a online RL algorithm for fine-tuning, and (3) initializing with the pre-trained policy and value function.
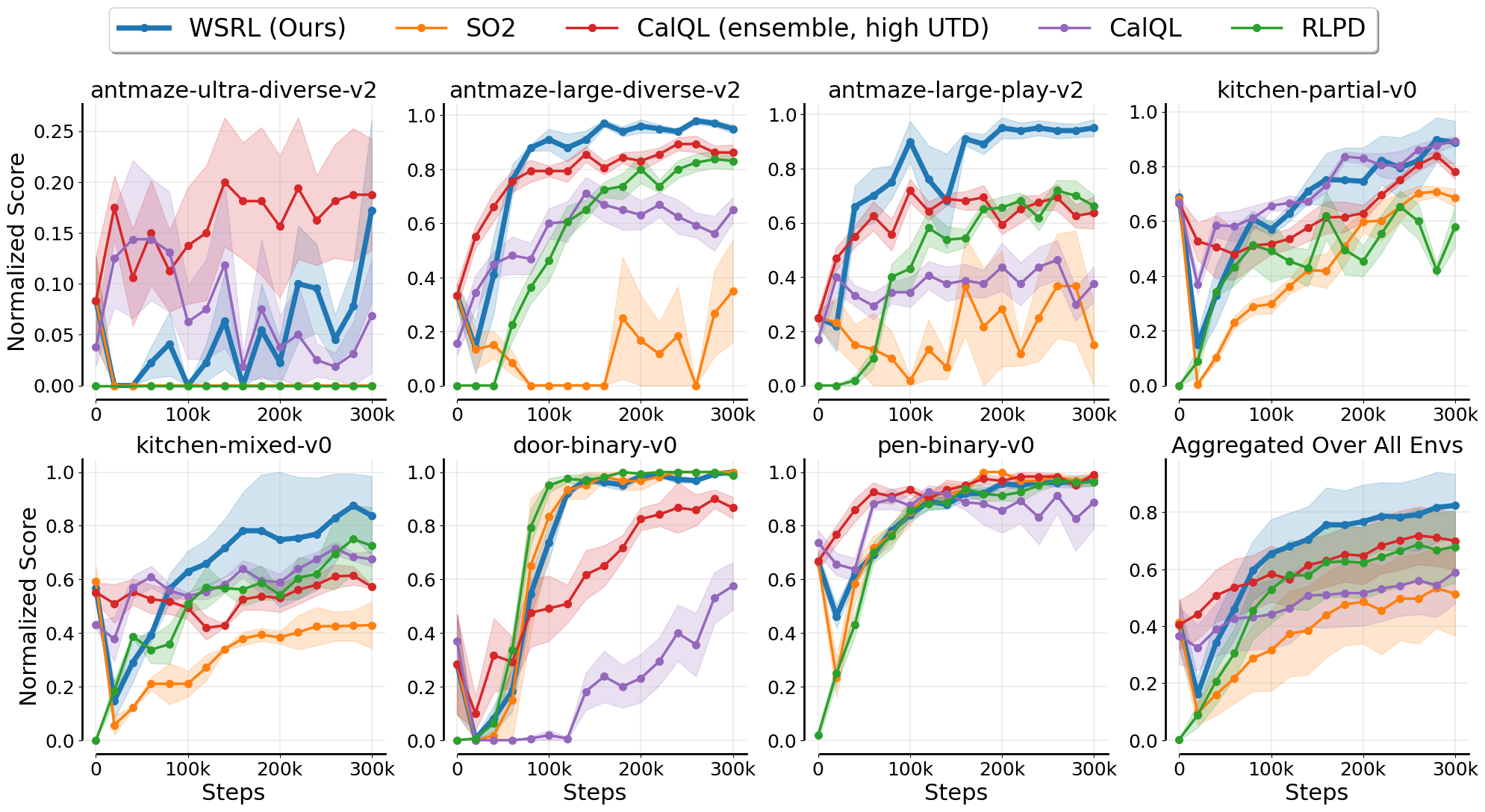
Even compared to methods that do retain offline data and therefore has access to more information during fine-tuning, WSRL is able to fine-tune faster or competitively without retaining offline training data.
@article{zhou2024efficient,
author = {Zhiyuan Zhou and Andy Peng and Qiyang Li and Sergey Levine and Aviral Kumar},
title = {Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data},
conference = {arXiv Pre-print},
year = {2024},
url = {http://arxiv.org/abs/2412.07762},
}