My research focuses on learning from imperfect real-world data with reinforcement learning. More broadly, my goal is to develop decision-making systems that can use prior knowledge from large-scale pre-training while continually improving from their own experience in the real world. I am especially interested in how robots can learn at scale from the full spectrum of real-world experience, including suboptimal demonstrations, autonomous rollouts, and failure data. Towards this goal, I work on various aspects of robotics and reinforcement learning, with a current focus on incorporating RL into robotic foundation models and post-training robotic policies to extremely high performance. I am fortunate to be advised by professor Sergey Levine at UC Berkeley. During my undergrad I was advised by professors George Konidaris and Michael Littman at Brown. Please check out my selected work below.
CV | Google Scholar | Github | Twitter
Publications
Conferences / Workshops
|
|
\(\pi^{*}_{0.6}\): a VLA that Learns from Experience
Robotics
VLA
RL
Ali Amin, Raichelle Aniceto,
...,
Zhiyuan Zhou
Robotics Science and Systems (RSS), 2026. [paper] [website] We train a VLA with offline RL through advantage conditioning, enabling the VLA to consume all robotic data, including suboptimal automonous trajectories and on-policy expert interventions. This doubles the task throughput and halves the failure rate on many challening long-horizon tasks, and enables long deployment time (13h) without failure. |
|
|
Robust Finetuning of Vision-Language-Action Robot Policies via Parameter Merging
Robotics
Yajat Yadav*,
Zhiyuan Zhou*,
Andrew Wagenmaker,
Karl Pertsch,
Sergey Levine
International Conference on Learning Representations (ICLR), 2026 [website] [paper] [code] Finetuning generalist policies easily overfits. Turns out that simply merging the weights of a pretrained and finetuned VLA model is surprisingly effective at robust finetuning, and is able to generalize to the finetuning task with different variations, in addition to maintaining generalist abilities. |
|
Reinforcement Learning with Action Chunking
deep reinforcement learning
Qiyang Li,
Zhiyuan Zhou,
Sergey Levine
NeurIPS, 2025 [paper] [website] [code]
Q-chunking runs RL on a temporally extended action (action chunking) space with an expressive behavior constraint to leverage prior data for improved exploration and online sample efficiency. |
|
Compute-Optimal Scaling for Value-Based Deep RL
RL, scaling laws
Preston Fu,
Oleh Rybkin,
Zhiyuan Zhou,
Michal Nauman,
Peter Abbeel,
Sergey Levine,
Aviral Kumar
NeurIPS, 2025 [paper]
Big models (TD-)overfit less and produce better TD targets, and allows for using bigger batch sizes. We analyze the interplay between model size, batch size, and UTD for scaling value-based RL, and show scaling laws that shows the budget-optimal data-compute tradeoff. |
|
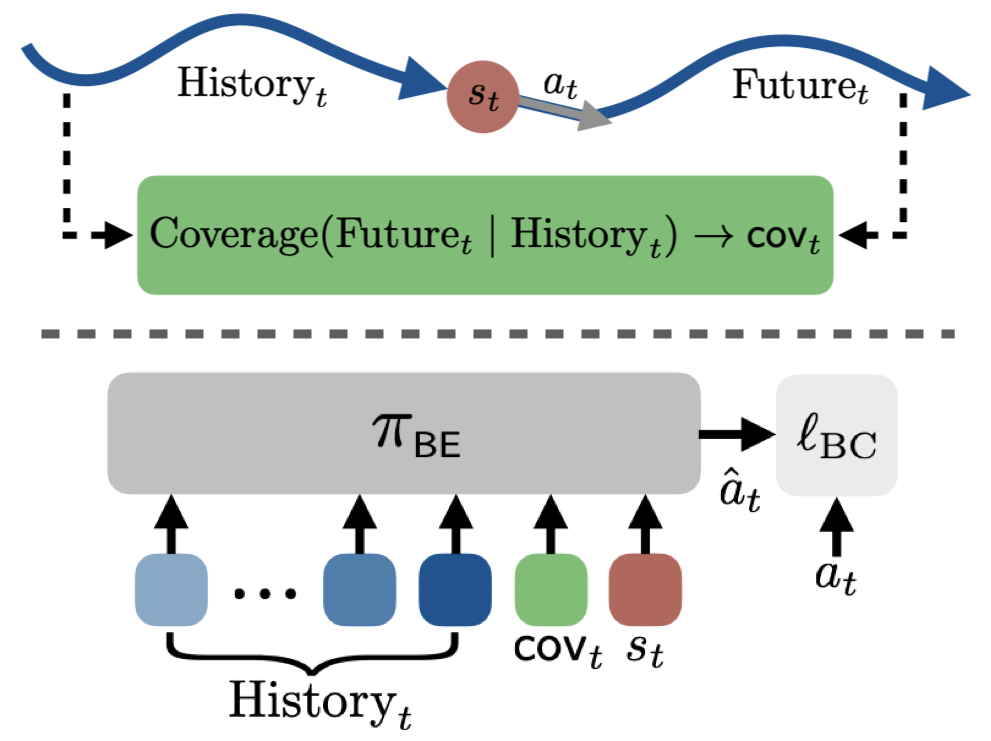
Behavioral Exploration: Learning to Explore via In-Context Adaptation
In-context learning
Andrew Wagenmaker,
Zhiyuan Zhou,
Sergey Levine
International Conference on Machine Learning (ICML), 2025 [paper]
Behavioral exploration (BE) seeks to train policies that can explore over the space of expert demonstration behaviors. We achieve this by training a long-context policy that's conditioned on history and a notion of "coverage-to-go". |
|
|
AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World
Robotics
Zhiyuan Zhou,
Pranav Atreya,
You Liang Tan,
Karl Pertsch,
Sergey Levine
Conference on Robot Learning (CoRL), 2025. ICLR Robot Learning Workshop, 2025. (Oral) RSS Robot Evaluation Workshop, 2025. (Best Paper) [paper] [website] [code] Evaluating generalist robot policies is very time consuming. We propose AutoEval, a system that autonomously evaluates generalist policies in the real world with learned success detectors and reset policies. We open access to two AutoEval stations for researchers to evaluate their policies. Submit your policy for evaluation in minutes! |
|
|
Learning Transferable Sub-Goals by Hypothesizing Generalizing Features
hierarchical RL
skill transfer
Anita de Mello Koch,
Akhil Bagaria,
Bingnan Huo,
Zhiyuan Zhou,
Cameron Allen,
George Konidaris
AAAI Workshop on Generalization in Planning, 2025. (Oral) [paper]
How do we transfer low level skills in hierarchical RL to make it sample efficient, especially in the context of one-shot and few-shot learning? We find that we can learn subgoals classifiers that transfer to unseen tasks with an ensemble of classifiers that focus on diverse features. |
|
|
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
deep reinforcement learning
fine-tuning
Zhiyuan Zhou*,
Andy Peng*,
Qiyang Li,
Sergey Levine,
Aviral Kumar
International Conference on Learning Representations (ICLR), 2025 [paper] [website] [code]
Can we finetune policies and values from offline RL *without retaining the offline data*? Current methods require keeping the offline data
for stability and performance, but this make RL hard to scale up when the offline dataset gets bigger and bigger. Turns out a simple recipe, Warm-start RL, is able to finetune rapidly without data retention! |
|
|
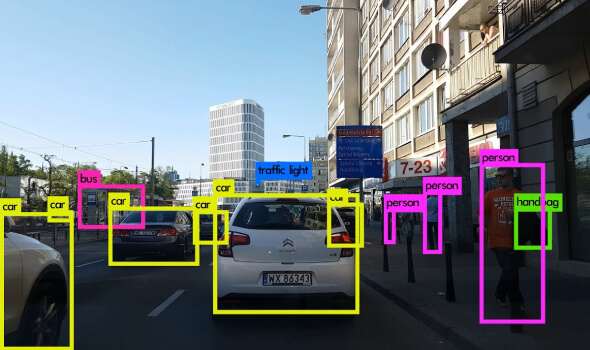
Autonomous Improvement of Instruction Following Skills via Foundation Models
robotics
autonomous improvement
language-conditioned skills
VLM
Zhiyuan Zhou*,
Pranav Atreya*,
Abraham Lee,
Homer Walke,
Oier Mees,
Sergey Levine
Conference on Robot Learning (CoRL), 2024. [website] [arXiv] [code] [dataset]
Can robots self-improve by collecting data autonomously🤖? We introduce SOAR, a system for large-scale autonomous data collection 🚀 and autonomous improvement📈of a multi-task language-conditioned policy in diverse scenes without human interventions . |
|
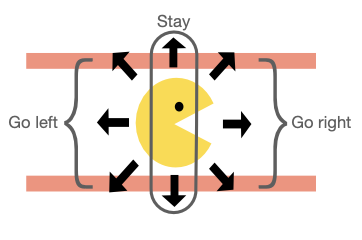
Tiered Reward: Designing Rewards for Specification and Fast Learning of Desired Behavior
behavior specification
reward design
Pareto optimality
fast learning
Zhiyuan Zhou,
Shreyas Sundara Raman,
Henry Sowerby,
Michael Littman
Reinforcement Learning Conference (RLC), 2024. [paper] [website] [code] [thread]
Do you need a reward function for your goal-reaching task? Use Tiered Reward! We prove that Tiered Reward guarantees to lead to an optimal policy, and show that it can lead to fast learning in various deep and tabular environments. |
|
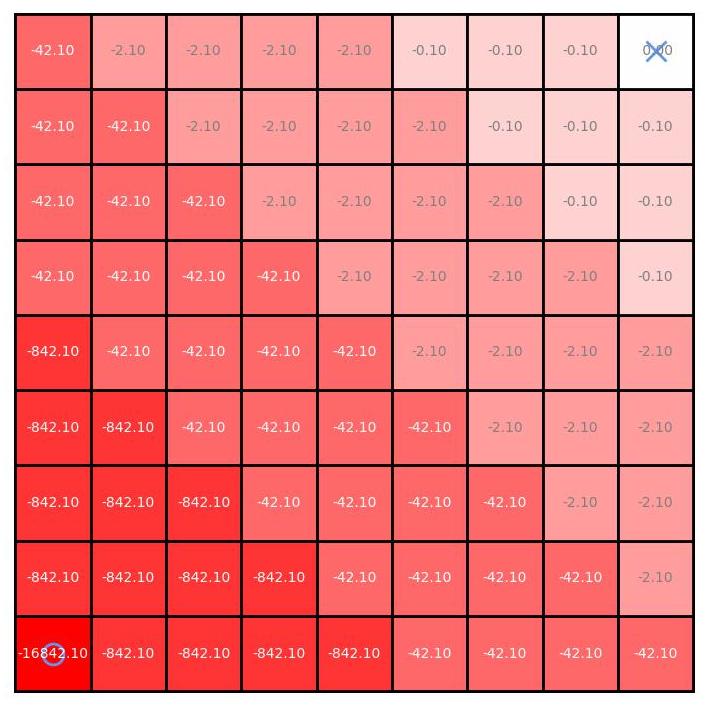
Characterizing the Action-Generalization Gap in Deep Q-Learning
action generalization
DQN
Zhiyuan Zhou,
Cameron Allen,
Kavosh Asadi,
George Konidaris
Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM), 2022. [arXiv] [poster] [code] We introduce a way to evaluate action-generalization in Deep Q-Learning using an oracle (expert knowledge of action similarity), and shows that DQN's ability to generalize over actions depends on the size of the action space. |

|
Designing Rewards for Fast Learning
reward design
Interactive RL
Henry Sowerby,
Zhiyuan Zhou,
Michael Littman
Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM), 2022. (Oral) [arXiv] [poster] [oral at RLDM at 1:20:00] What kind of reward functions make RL fast? We advocate for rewards with big action gaps and small "subjective discounts". We present an algorithm to design these rewards. |
School Journal

|
Policy Transfer in Lifelong Reinforcement Learning through Learning Generalizing Features
lifelong RL
transfer learning
attention
Zhiyuan Zhou (Advisor: George Konidaris)
Undergraduate Honors Thesis, Brown CS, 2023. [pdf] [code]
Introduces an approach to learn state features that generalize across tasks drawn from the same distribution. We use an attantion mechanism to learn an ensemble of minimally overlapping state features, leading to an ensemble of policies. We then use a bandit algorithm to learn to identify the generalizing feature in the ensemble and capitalize on that to learn a transferable policy. |
|
Improving Post-Processing on Video Object Recognition Using Inertial Measurement Unit
object recognition
Hidden Markov Models
Kalman Filter
Inertial Measurement Unit
Zhiyuan Zhou,
Spencer Boyum,
Michael Paradiso
Brown Undergraduate Research Journal, Spring 2022. [paper on page 29] [code] How to improve the accuracy of object recognition in videos if given per-frame inertial measurements of the camera. We propose two way to do so. |